01. 基础教程¶
在这个教程中,您将学习到:
定义搜索空间
优化目标函数
通过这个教程,您无需理解UltraOpt所实现算法的任何数学原理,就可以通过UltraOpt去优化超参数。
[1]:
# import fmin interface from UltraOpt
from ultraopt import fmin
# hdl2cs can convert HDL(Hyperparams Describe Language) to CS(Config Space)
from ultraopt.hdl import hdl2cs
声明要优化的评价函数。在本教程中,我们将优化一个名为evaluate的简单函数,它是一个简单的二次函数。需要注意的是在我们的定义中,评价函数接受参数config返回loss,loss越小表示配置越好。
[2]:
def evaluate(config:dict):
x = config["x"]
return (x-3)**2 + 2
现在,让我们可视化这个目标函数。
[3]:
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-10, 10, 100)
y = [evaluate({"x": xi}) for xi in x]
fig = plt.figure()
plt.plot(x, y)
plt.xlabel("x")
plt.ylabel("evaluate")
plt.show()
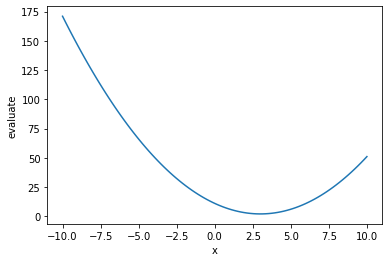
我们试图通过改变超参数\(x\)来优化目标函数。这就是为什么我们要声明一个\(x\)的搜索空间。与搜索空间相关的函数在ultraopt.hdl.hp_def中实现. 列举如下。
{"_type": "choice", "_value": options}{"_type": "ordinal", "_value": sequence}{"_type": "uniform", "_value": [low, high]}{"_type": "quniform", "_value": [low, high, q]}{"_type": "loguniform", "_value": [low, high]}{"_type": "qloguniform", "_value": [low, high, q]}{"_type": "int_uniform", "_value": [low, high]}{"_type": "int_quniform", "_value": [low, high, q]}
HDL(超参描述语言)是一种参考nni[1]的搜索空间[2]而实现的一种超参数描述方法,UltraOpt通过ultraopt.hdl.hdl2cs函数将HDL转换成配置空间(ConfigSpace[3],
一种在AutoSklearn[4], HpBandSter[5]等库中大量采用的基础库)
HDL的编写方法为{"变量名": 超参范围描述, ...},本例的HDL如下:
[4]:
HDL = {
"x":{ # 变量名为 x
"_type": "uniform", # 变量类型为 uniform
"_value": [-10, 10] # 变量取值范围为 low = -10, hight = 10
}
}
通过 ultraopt.hdl.hdl2cs 函数将HDL转换为CS
[5]:
CS = hdl2cs(HDL)
CS
[5]:
Configuration space object:
Hyperparameters:
x, Type: UniformFloat, Range: [-10.0, 10.0], Default: 0.0
配置空间CS是具有采样功能的,我们从中随机采5个样本,并将其转换为dict类型
[6]:
configs = [config.get_dictionary() for config in CS.sample_configuration(5)]
configs
[6]:
[{'x': 2.99612580326402},
{'x': 0.028681287154995516},
{'x': 0.34249434531803047},
{'x': -3.5600965460908807},
{'x': -2.049214213069341}]
对每个configs都调用objective函数评估一次,获取其目标值,对于目标值最小的,就是我们想要的最佳配置。
以上步骤其实就是一次最简单的黑箱优化流程。
[7]:
import numpy as np
losses = [evaluate(config) for config in configs]
best_ix = np.argmin(losses)
print(f"optimal config: {configs[best_ix]}, \noptimal loss: {losses[best_ix]}")
optimal config: {'x': 2.99612580326402},
optimal loss: 2.0000150094003493
在学习了超参空间定义、采样、评估等黑箱优化流程后,我们希望能够用一个工具将这些步骤串起来,并希望使用启发式的优化算法而不是随机搜索。此时我们可以采用UltraOpt的fmin函数,这个函数需要定义4个重要的参数:
参数名 |
描述 |
|---|---|
eval_func |
评价函数,接受config参数( |
config_space |
配置空间,可以传入HDL( |
optimizer |
优化器。在使用优化器默认参数的情况下,您只需要指定优化器的名字,列举如下。 |
n_iterations |
迭代次数,在不考虑多保真优化的情况下可视为评价函数执行次数 |
优化器 |
描述 |
|---|---|
ETPE |
Embedding-Tree-Parzen-Estimator, 是UltraOpt作者 自创的一种优化算法,在TPE算法[9]的基础上对类别变量采用Embedding降维为低维连续变量,并在其他的一些方面也做了改进。ETPE在某些场景下表现比HyperOpt的TPE算法要好。 |
Forest |
基于随机森林的贝叶斯优化算法。概率模型引用
了 |
GBRT |
基于梯度提升回归树(Gradient Boosting Resgression Tree)的贝叶斯优化算法,概率模型引用了 |
Random |
随机搜索。 |
[8]:
result = fmin(
eval_func=evaluate, # 评价函数
config_space=HDL, # 配置空间
optimizer="Forest", # 优化器
n_iterations=100 # 迭代数
)
100%|██████████| 100/100 [00:03<00:00, 26.12trial/s, best loss: 2.000]
ultraopt.min函数的返回值result自带优化结果汇总表
[9]:
result
[9]:
+---------------------------------+
| HyperParameters | Optimal Value |
+-----------------+---------------+
| x | 3.0014 |
+-----------------+---------------+
| Optimal Loss | 2.0000 |
+-----------------+---------------+
| Num Configs | 100 |
+-----------------+---------------+
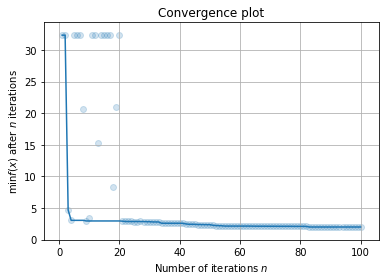
查看优化过程的拟合曲线:
[13]:
result.plot_convergence();
参考文献
